Case study: MariaDB ColumnStore

A recent project I worked on provided an opportunity to work with MariaDB ColumnStore.
The Product
The product is a business intelligence application. Its main view, a very comprehensive dashboard with an abundance of counters, showing all operational aspects: from server status, database backups, support tickets and SLA to datacenter atmospheric conditions.
In the middle of all this: several MariaDB databases fed through multiple ETL jobs.
As the application grew, the dashboard got increasingly more intricate. The tables got bigger and the queries slower. To cope with the higher load, aggregate tables were added at some point. These tables contained precomputed subtotals for various predefined filters.
The Issue
The aggregate tables worked really well for a very long time. However, it still had its downsides, all of which got worse as data ingestion rate increased:
- db schema and operation gets more complex
- tables need to be updated frequently as new data is added
- higher resource utilization, locks and timeouts during update jobs
- even on the best cases, some lag between precomputed and actual data is always present
That last one was causing the big trouble. Dashboards where getting out of date fast, new data was being added faster than it could be processed. As a result, users where more frequently seeing stale data.
The Requirements
The main requirement is to have the dashboards to be as close as possible to real time, while keeping page load times within reason.
Several solutions were proposed, including partitioning, sharding and adding more replication slaves. After talking and discussing options, we settled trying out MariaDB ColumnStore.
Some reasons we thought it would be a good solution:
- Familiarity: They were already running MySQL and MariaDB.
- Simplicity: We could get rid of the aggregate tables and their update processes.
- Integration: No need to overhaul the whole setup, we could copy the tables at our convenience.
The ColumnStore
MariaDB ColumnStore (CS) is a special version of MariaDB, it supports all the traditional MariaDB features while providing an additional storage engine: ColumnStore, for columnar-based tables.
But while MariaDB has a 1 query = 1 CPU restriction, CS is all about parallelism. Not only a single query can be processed by multiple CPUs: queries can be distributed among multiple CS servers,
The Test
For the test I was given a modest VM with 8 CPUs and 15 GB of RAM. We picked a pilot table, extracted one month worth of data from the table (about 5M rows) and proceded to run the tests.
As a “control group”, a vanilla MariaDB server was installed and the usual production queries were benchmarked.
Then the second phase began: after removing MariaDB, a CS server was installed and data imported in a ColumnStore table. Again, bechmarks were run.
Here are the times to compute an aggregate table:
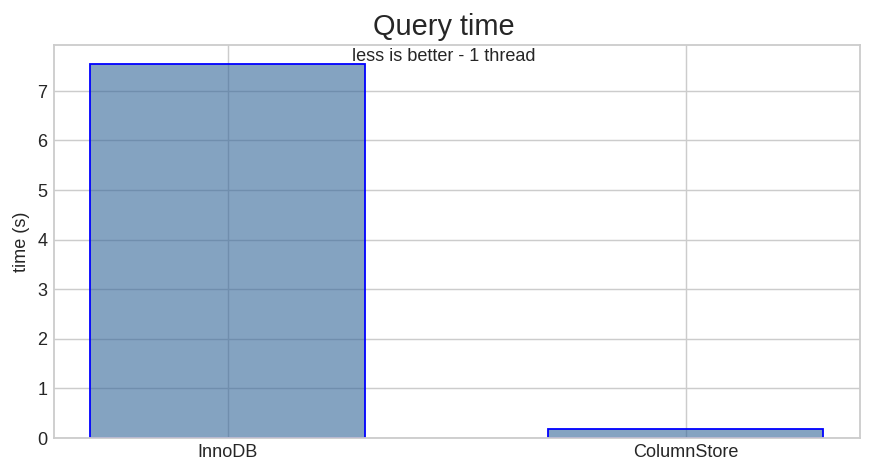
| InnoDB | ColumnStore | |
|---|---|---|
| Query Time | 7.549 s | 0.169 s |
Quite impressive: about 44 times faster.
We can’t claim victory yet, as this does not really reflect the actual user experience. Remember the app is fed from the precomputed aggregate table.
The real test is about estimating page load time. How does the realtime aggregation compares against getting the precomputed table?
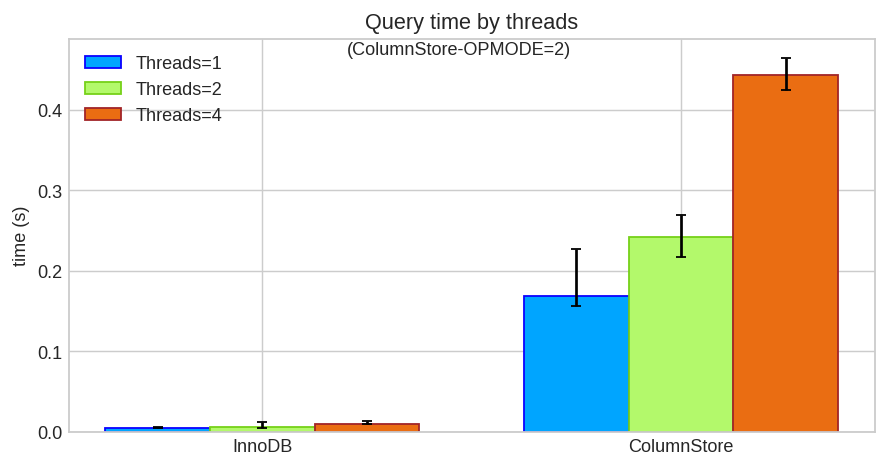
| Query Time | 1 thread | 2 threads | 4 threads |
|---|---|---|---|
| InnoDB | 0.005 s | 0.006 s | 0.010 s |
| ColumnStore | 0.169 s | 0.242 s | 0.443 s |
From the user perspective, performance with CS is worse, the page load time increases in about 2 orders of magnitude. True, the data show is as realtime as possible. But can we do better?
Yes, of course. So far we only scratched the surface.
MariaDB ColumnStore has 3 modes of operation, these can be set at global level or session level:
- Mode 0: generic row-by-row mode, highly compatible but much slower.
- Mode 1: distributed, very fast but non-parallelizable queries are rejected.
- Mode 2: automatic, switches between mode 0 and 1 depending on query.
Mode 1 is the default, which means it wants to be fed good queries. To make the previous tests work, I had to switch to mode 0, so we’re not getting the best possible performance.
With a surprisingly little bit of rewriting, the same queries were running on mode 1.
Let’s see how well it does:
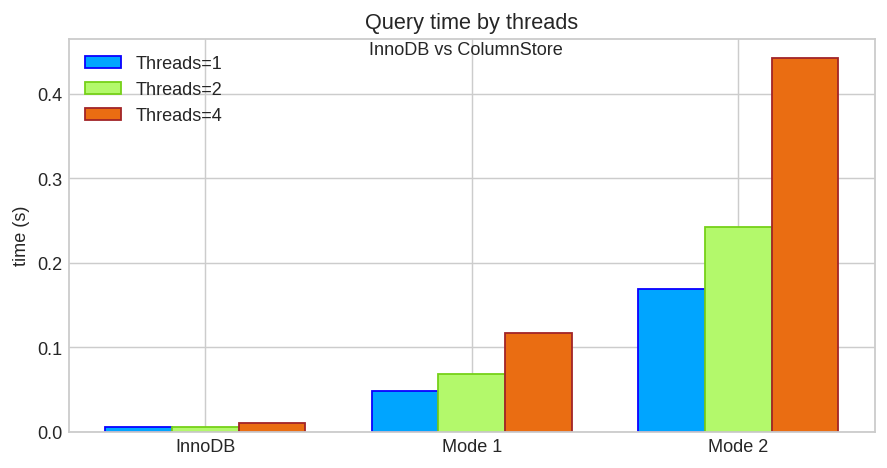
| Query Time | 1 thread | 2 threads | 4 threads |
|---|---|---|---|
| InnoDB (aggregate) | 0.005 s | 0.006 s | 0.010 s |
| ColumnStore (mode 1) | 0.048 s | 0.068 s | 0.117 s |
| ColumnStore (mode 0) | 0.169 s | 0.242 s | 0.443 s |
Query times improved a lot, realtime mode 1 takes only 1 order of magnitude more than getting the precomputed data, that’s quite a feat. Page load times are still worse, but it’s very much within the usual latency for a web application.
The Solution
Once the plan was green-lighted, I proceeded to install a proper CS server (only one node for now, but we can add more later).
To provide load-balancing a MariaDB MaxScale proxy was added. This proved a key component as it also allows to capture changes on the main db, which are then sent to CS without needing to modify any other processes.
With proper load balancing in place, we took to opportunity to add more slave replicas to increase the performance of the general queries.
Caveats
Some problems we encountered along the way:
- Not all queries were as easy to optimize for mode 1.
- Not all aggregation functions are available for CS tables:
Things like
SUM(FIND_IN_SET(code,'0,1'))don’t work. In some cases, we had to add additional columns to work around this.
- Datatypes in CS are more strict than in MariaDB, JOINS require types to match much more closely.
- Some queries where trying to aggregate too many columns at a time, which probably made sense of a Row based database. But for CS we found it’s better to split them in separate queries.
- Big joins can fail due to lack of memory, disk-based joins are disabled by default. Enabling the feature fixes the issue, but performance goes down fast. As a result, we had to tweak joins and where conditions on some queries.
Related links
- MariaDB ColumnStore: https://mariadb.com/kb/en/library/mariadb-columnstore/
- Operating modes: https://mariadb.com/kb/en/library/columnstore-operating-mode/
- Aggregate functions: https://mariadb.com/kb/en/library/columnstore-distributed-aggregate-functions/
- MariaDB MaxScale: https://mariadb.com/kb/en/maxscale/
- Change Data Capture: https://mariadb.com/kb/en/mariadb-maxscale-22-change-data-capture-cdc-protocol/
Thanks
I’d like to thank the customer who very graciously allowed me to publish this entry and share the experience.
Later
Tomas